Linear regression is one of the most fundamental algorithms in machine learning. It models the relationship between input features (independent variables) and an output (dependent variable) by fitting a straight line. Despite its simplicity, linear regression is widely used in business forecasting, trend analysis, and scientific research.
In this tutorial, you’ll learn how to build a linear regression model from scratch on an Ubuntu 24.04 GPU server.
Prerequisites
- An Ubuntu 24.04 server with an NVIDIA GPU.
- A non-root user or a user with sudo privileges.
- NVIDIA drivers are installed on your server.
Step 1 – Set Up the Environment
Before building the model, you need a proper Python environment with the right libraries installed. Since we’re working on Ubuntu 24.04 with GPU support, we’ll prepare a virtual environment and install PyTorch with CUDA, along with data and plotting libraries.
1. Install required packages.
apt install -y python3 python3-pip python3-venv git2. Create and activate a virtual environment.
python3 -m venv venv
source venv/bin/activate3. Install additional dependencies.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install numpy matplotlib pandas4. Verify the GPU availability.
python3 -c "import torch; print(torch.cuda.is_available())"Output.
TrueIf you see True, your server is ready to train models with GPU acceleration.
Step 2 – Generate a Sample Dataset
To train and test our linear regression model, we first need some data. Instead of using a public dataset, we’ll generate a simple one based on a known equation:
y=4+3X+noiseThis will allow us to verify whether our model can correctly learn the intercept (4) and slope (3).
1. Create the data generation script.
nano generate_data.pyAdd the following code.
#!/usr/bin/env python3
import numpy as np
import pandas as pd
# Generate random data
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) # y = 4 + 3X + noise
# Save to CSV
data = np.hstack([X, y])
df = pd.DataFrame(data, columns=["X", "y"])
df.to_csv("linear_data.csv", index=False)
print("Dataset saved as linear_data.csv")2. Run the script to generate the dataset.
python3 generate_data.pyOutput.
Dataset saved as linear_data.csvNow we have a clean dataset stored in linear_data.csv that we’ll use for training both CPU and GPU versions of our linear regression model.
Step 3 – Build Linear Regression from Scratch
Now that we have our dataset, let’s build a linear regression model from scratch using only NumPy. This will help us understand how gradient descent optimizes parameters step by step.
1. Create the script.
nano linear_regression.pyAdd the following code.
#!/usr/bin/env python3
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Load dataset
data = pd.read_csv("linear_data.csv")
X = data["X"].values.reshape(-1, 1)
y = data["y"].values.reshape(-1, 1)
# Add bias column (for intercept term)
X_b = np.c_[np.ones((X.shape[0], 1)), X]
# Initialize parameters (theta = [bias, weight])
theta = np.random.randn(2, 1)
# Hyperparameters
learning_rate = 0.1
iterations = 1000
m = len(X)
# Gradient Descent
for i in range(iterations):
gradients = (2/m) * X_b.T.dot(X_b.dot(theta) - y)
theta -= learning_rate * gradients
print("Learned parameters (intercept, slope):", theta.ravel())
# Predictions
y_pred = X_b.dot(theta)
# Plot
plt.scatter(X, y, color="blue", label="Data")
plt.plot(X, y_pred, color="red", label="Prediction")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.savefig("regression_plot.png")
plt.show()2. Run the model.
python3 linear_regression.pyOutput.
Learned parameters (intercept, slope): [4.21509616 2.77011339]The script generates a plot regression_plot.png that shows:
- Blue dots → Original dataset.
- Red line → Predicted regression line.
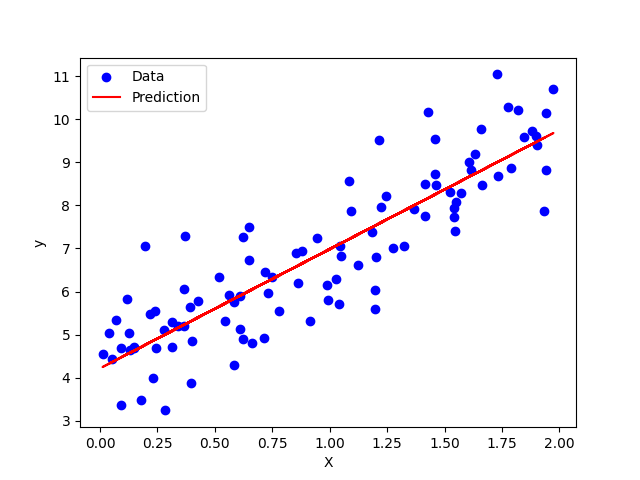
This confirms that our model successfully approximated the real equation y=4+3X even with added noise.
Step 4 – Accelerate with GPU (PyTorch)
Our NumPy implementation works well, but training larger datasets can be slow on the CPU. To speed things up, we’ll use PyTorch and run the training on the GPU.
1. Create a script.
nano linear_regression_gpu.pyAdd the following code.
#!/usr/bin/env python3
import torch
import pandas as pd
import numpy as np
# Load dataset
data = pd.read_csv("linear_data.csv")
X = data["X"].values.reshape(-1, 1)
y = data["y"].values.reshape(-1, 1)
# Add bias column (for intercept term)
X_b = np.c_[np.ones((X.shape[0], 1)), X]
# Select device
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
# Convert data to torch tensors
X_tensor = torch.tensor(X_b, dtype=torch.float32).to(device)
y_tensor = torch.tensor(y, dtype=torch.float32).to(device)
# Initialize parameters (theta = [bias, weight])
theta = torch.randn((2,1), dtype=torch.float32, device=device, requires_grad=True)
# Optimizer
optimizer = torch.optim.SGD([theta], lr=0.1)
# Training loop
for i in range(1000):
y_pred = X_tensor @ theta
loss = torch.mean((y_pred - y_tensor) ** 2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Learned parameters on GPU:", theta.detach().cpu().numpy().ravel())2. Run the training on your GPU.
python3 linear_regression_gpu.pyOutput.
Using device: cuda
Learned parameters on GPU: [4.215091 2.7701175]Notice how the learned values are almost identical to those from the CPU version:
- CPU: [4.21509616, 2.77011339]
- GPU: [4.215091, 2.7701175]
Both converge close to the true equation y=4+3X. The main advantage of GPU computation is speed, which becomes significant with much larger datasets.
Conclusion
In this tutorial, you learned how to build a linear regression model from scratch on an Ubuntu 24.04 GPU server. Starting from a synthetic dataset, you implemented gradient descent manually with NumPy on the CPU, then accelerated the same process with PyTorch on the GPU.
* This post is for informational purposes only and does not constitute professional, legal, financial, or technical advice. Each situation is unique and may require guidance from a qualified professional.
Readers should conduct their own due diligence before making any decisions.