Cybersecurity threats continue to grow, and malicious URLs have become one of the most common vectors for phishing, malware delivery, and other online attacks. Detecting these URLs manually or using traditional blacklists is often ineffective because attackers can easily generate new domains to evade detection.
This is where machine learning comes in. By learning patterns from known malicious and benign URLs, a machine learning model can generalize and classify previously unseen URLs more effectively than static rules or blocklists.
In this guide, we will build a comprehensive machine learning pipeline for detecting malicious URLs.
Prerequisites
- An Ubuntu 24.04 server with an NVIDIA GPU.
- A non-root user or a user with sudo privileges.
- NVIDIA drivers are installed on your server.
Step 1: Set up Python Environment
Before we build and deploy our malicious URL detection pipeline, we need to set up a proper development environment on server.
1. Install required dependencies.
apt install -y python3 python3-pip python3-venv2. Create a Python virtual environment.
python3 -m venv url-venv
source url-venv/bin/activate3. Upgrade pip to the latest version.
pip install --upgrade pip4. Install required Python packages.
pip3 install -U -q scikit-learn joblib seaborn colorama tld plotly whois wordcloud gensim nltk tldextract hmmlearn xgboost lightgbm catboost flaskStep 2: Download the Dataset
Now that our environment is ready, we need to get the dataset onto the server and prepare it for machine learning. The dataset we’ll use contains labeled malicious and benign URLs, and it’s available from Kaggle.
1. On your server, create a directory for the project.
mkdir /root/project2. Next, download the dataset from Kaggle on your local machine.
3. Use scp (secure copy) to upload the dataset from your local machine to the server.
scp Downloads/malicious_phish.csv.zip root@your-server-ip:/root/project/4. On the server, navigate to the project directory and unzip the dataset file.
cd /root/project
unzip malicious_phish.csv.zipYou should now see malicious_phish.csv in the /root/project directory.
Step 3: Model Training and Evaluation
With our dataset prepared, we are ready to train the machine learning model that will classify URLs as benign, phishing or malicious.
1. Create the training script.
nano malicious_url_detection.pyAdd the following code:
import pandas as pd
import numpy as np
import hashlib
import re
import ipaddress
from urllib.parse import urlparse
import tldextract
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.pipeline import Pipeline
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, classification_report
import joblib
# ----------------------
# Utility functions
# ----------------------
def get_url_length(url):
prefixes = ['http://', 'https://']
for prefix in prefixes:
if url.startswith(prefix):
url = url[len(prefix):]
url = url.replace('www.', '')
return len(url)
def count_letters(url): return sum(c.isalpha() for c in url)
def count_digits(url): return sum(c.isdigit() for c in url)
def count_special_chars(url): return sum(c in "!@#$%^&*()_+-=[]{};:,.<>/?`~|" for c in url)
def has_shortening_service(url):
pattern = re.compile(r'bit\.ly|goo\.gl|tinyurl|t\.co|ow\.ly|bitly|is\.gd|cutt\.ly')
return int(bool(pattern.search(url)))
def abnormal_url(url):
parsed = urlparse(url)
hostname = parsed.hostname
return int(bool(hostname and re.search(hostname, url)))
def secure_http(url):
return int(urlparse(url).scheme == 'https')
def have_ip_address(url):
try:
parsed = urlparse(url)
if parsed.hostname:
ip = ipaddress.ip_address(parsed.hostname)
return isinstance(ip, (ipaddress.IPv4Address, ipaddress.IPv6Address))
except ValueError:
return 0
return 0
def hash_encode(val):
return int(hashlib.md5(val.encode()).hexdigest(), 16) % (10 ** 8)
# ----------------------
# Load dataset
# ----------------------
data = pd.read_csv("malicious_phish.csv") # replace with your actual file path
print(f"Loaded dataset: {data.shape[0]} rows")
# ----------------------
# Label encoding
# ----------------------
label_mapping = {'benign': 0, 'defacement': 1, 'phishing': 2, 'malware': 3}
data['url_type'] = data['type'].map(label_mapping)
# ----------------------
# Feature engineering
# ----------------------
data['url_len'] = data['url'].apply(lambda x: get_url_length(str(x)))
data['letters_count'] = data['url'].apply(lambda x: count_letters(str(x)))
data['digits_count'] = data['url'].apply(lambda x: count_digits(str(x)))
data['special_chars_count'] = data['url'].apply(lambda x: count_special_chars(str(x)))
data['shortened'] = data['url'].apply(lambda x: has_shortening_service(str(x)))
data['abnormal_url'] = data['url'].apply(lambda x: abnormal_url(str(x)))
data['secure_http'] = data['url'].apply(lambda x: secure_http(str(x)))
data['have_ip'] = data['url'].apply(lambda x: have_ip_address(str(x)))
data['root_domain'] = data['url'].apply(lambda x: hash_encode(tldextract.extract(str(x)).domain))
data['url_region'] = data['url'].apply(lambda x: hash_encode(x.split('.')[-1]))
# ----------------------
# Prepare dataset for training
# ----------------------
feature_cols = [
'url_len', 'letters_count', 'digits_count', 'special_chars_count',
'shortened', 'abnormal_url', 'secure_http', 'have_ip',
'url_region', 'root_domain'
]
X = data[feature_cols]
y = data['url_type']
print(f"Feature matrix: {X.shape}")
print(f"Labels: {y.shape}")
# ----------------------
# Train-test split
# ----------------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# ----------------------
# Train model
# ----------------------
clf = Pipeline([('classifier', ExtraTreesClassifier(random_state=42))])
clf.fit(X_train, y_train)
# ----------------------
# Evaluate model
# ----------------------
y_pred = clf.predict(X_test)
print("\nClassification report on test set:")
print(classification_report(y_test, y_pred))
# ----------------------
# Save model
# ----------------------
joblib.dump(clf, "eTc.sav")
print("\n✅ Model saved as eTc.sav")
# ----------------------
# Save feature column order for consistency
# ----------------------
joblib.dump(feature_cols, "feature_order.sav")
print("✅ Feature order saved as feature_order.sav")The above script:
- Loads the dataset
- Applies feature engineering
- Splits the data into training and testing sets
- Trains an ensemble classifier (ExtraTreesClassifier)
- Evaluates model performance
- Saves both the trained model and the feature order for later inference
2. Run the training script.
python3 malicious_url_detection.pyOutput.
Classification report on test set:
precision recall f1-score support
0 0.95 0.98 0.96 128733
1 0.91 0.98 0.94 28692
2 0.87 0.68 0.77 28234
3 0.98 0.92 0.95 9699
accuracy 0.93 195358
macro avg 0.93 0.89 0.90 195358
weighted avg 0.93 0.93 0.93 195358
✅ Model saved as eTc.sav
✅ Feature order saved as feature_order.savThis shows strong predictive performance overall, with a weighted average accuracy of around 93%.
Step 4: Build Flask App
Now that our malicious URL detection model is trained and saved, the next step is to make it accessible via a simple web interface. We’ll use Flask, a lightweight Python web framework, to deploy the model, allowing users to submit URLs and receive predictions in real-time.
1. Create an application file.
nano app.py Add the following code.
from flask import Flask, render_template, request
import joblib
import numpy as np
import pandas as pd
import re
import hashlib
from urllib.parse import urlparse
import tldextract
import ipaddress
app = Flask(__name__)
# Load trained model and feature order
model = joblib.load('eTc.sav')
feature_cols = joblib.load('feature_order.sav')
class_mapping = {0: 'Benign', 1: 'Defacement', 2: 'Phishing', 3: 'Malware'}
TRUSTED_DOMAINS = ['google.com', 'youtube.com', 'facebook.com', 'github.com', 'amazon.com']
# Utility functions
def get_url_length(url):
prefixes = ['http://', 'https://']
for prefix in prefixes:
if url.startswith(prefix):
url = url[len(prefix):]
url = url.replace('www.', '')
return len(url)
def count_letters(url): return sum(c.isalpha() for c in url)
def count_digits(url): return sum(c.isdigit() for c in url)
def count_special_chars(url): return sum(c in "!@#$%^&*()_+-=[]{};:,.<>/?`~|" for c in url)
def has_shortening_service(url):
pattern = re.compile(r'bit\.ly|goo\.gl|tinyurl|t\.co|ow\.ly|bitly|is\.gd|cutt\.ly')
return int(bool(pattern.search(url)))
def abnormal_url(url):
parsed = urlparse(url)
hostname = parsed.hostname
return int(bool(hostname and re.search(hostname, url)))
def secure_http(url):
return int(urlparse(url).scheme == 'https')
def have_ip_address(url):
try:
parsed = urlparse(url)
if parsed.hostname:
ip = ipaddress.ip_address(parsed.hostname)
return isinstance(ip, (ipaddress.IPv4Address, ipaddress.IPv6Address))
except ValueError:
return 0
return 0
def hash_encode(val):
return int(hashlib.md5(val.encode()).hexdigest(), 16) % (10 ** 8)
def get_features(url):
url_len = get_url_length(url)
letters_count = count_letters(url)
digits_count = count_digits(url)
special_chars_count = count_special_chars(url)
shortened = has_shortening_service(url)
abnormal = abnormal_url(url)
secure_https = secure_http(url)
have_ip = have_ip_address(url)
root_domain = hash_encode(tldextract.extract(url).domain)
url_region = hash_encode(url.split('.')[-1])
return {
'url_len': url_len,
'letters_count': letters_count,
'digits_count': digits_count,
'special_chars_count': special_chars_count,
'shortened': shortened,
'abnormal_url': abnormal,
'secure_http': secure_https,
'have_ip': have_ip,
'url_region': url_region,
'root_domain': root_domain
}
@app.route('/', methods=['GET', 'POST'])
def index():
prediction = None
if request.method == 'POST':
url = request.form['url']
parsed_url = urlparse(url)
hostname = parsed_url.hostname or ''
if any(trusted in hostname.lower() for trusted in TRUSTED_DOMAINS):
prediction = 'Benign (trusted domain override)'
else:
feature_dict = get_features(url)
feature_values = [feature_dict[col] for col in feature_cols]
features_df = pd.DataFrame([feature_values], columns=feature_cols)
pred_idx = model.predict(features_df)[0]
prediction = class_mapping.get(pred_idx, 'Unknown')
return render_template('index.html', prediction=prediction)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)The above script does the following:
- Loads the trained model (eTc.sav) and saved feature columns (feature_order.sav)
- Accepts URL input from users via a web form
- Extracts features from the input URL (using the same feature engineering logic as during training)
- Returns the predicted classification (Benign, Defacement, Phishing, or Malware)
2. Create a templates directory and an index.html file that defines the user interface.
mkdir templates
nano templates/index.htmlAdd the following code.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Malicious URL Detector</title>
<style>
body { font-family: Arial; background: #282c34; color: #ffffff; text-align: center; padding: 50px; }
input[type="text"] { width: 60%; padding: 10px; font-size: 1em; }
input[type="submit"] { padding: 10px 20px; font-size: 1em; }
.result { margin-top: 20px; font-size: 1.2em; }
</style>
</head>
<body>
<h1>🔒 Malicious URL Detector</h1>
<form method="post">
<input type="text" name="url" placeholder="Enter URL here" required>
<input type="submit" value="Check URL">
</form>
{% if prediction %}
<div class="result">
<strong>Prediction:</strong> {{ prediction }}
</div>
{% endif %}
</body>
</html>Step 5: Run the Flask App and Access the Web UI
At this point, our Flask web application is ready to serve predictions using the trained malicious URL detection model. Let’s go over how to start the app and access it from your browser.
1. Start the Flask server with the following command.
python3 app.pyOutput.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://149.28.70.3:5000
Press CTRL+C to quit
* Restarting with stat
* Debugger is active!
* Debugger PIN: 759-456-0182. Open your web browser and access the Flask App using the URL http://your-server-ip:5000. You should see the “Malicious URL Detector” interface
3. Enter a suspicious-looking or synthetic malicious URL in the text box and click on Check URL. The app will analyze the URL, extract its features, classify it and show the response below the text box.
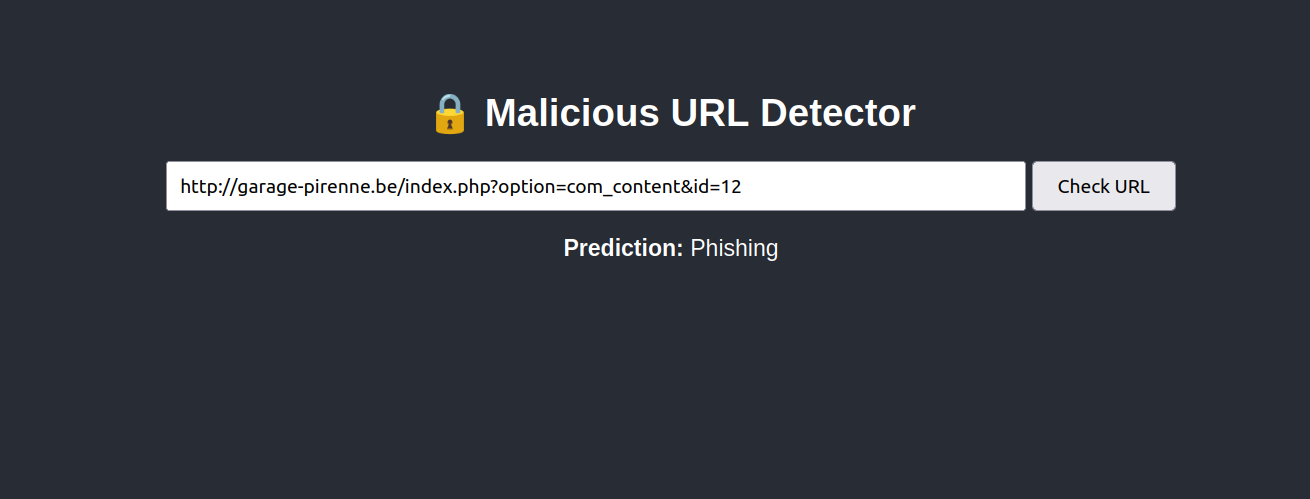
Conclusion
In this guide, we developed a comprehensive machine learning pipeline for detecting malicious URLs on an Ubuntu 24.04 GPU server. Starting from environment setup, we prepared the dataset, engineered meaningful features, and trained a robust classification model using ExtraTreesClassifier.
We then deployed the trained model as a user-friendly web application using Flask, allowing real-time predictions through a simple browser interface. Users can now submit any URL and immediately get a prediction: whether it is benign, defacement, phishing, or malware.
* This post is for informational purposes only and does not constitute professional, legal, financial, or technical advice. Each situation is unique and may require guidance from a qualified professional.
Readers should conduct their own due diligence before making any decisions.