Training AI models, creating complex deep learning networks, and processing the large-scale datasets required for AI applications demands a significant level of processing power, often exceeding the capabilities of traditional server hardware. As AI adoption scales in 2026, compute demand is increasing not just for training but also for real-time inference workloads.
The Graphics Processing Unit (GPU) has become instrumental for AI and ML development in recent years. Initially engineered for gaming and rendering visuals, GPUs possess a complex architecture that’s optimized for the mathematical operations needed by AI workloads. In 2026, GPUs remain the standard for both training large models and serving production AI systems.
To unlock the full potential of AI workloads, organizations can deploy on cloud GPU hosting (such as Atlantic.Net GPU Hosting) for its scalable, cost-effective, and high-performance infrastructure. Cloud-based GPU access is now the default approach for most AI teams rather than on-premise deployments.
In this article, we’ll cover:
- Why GPUs outperform traditional CPUs for demanding AI workloads.
- The key advantages of accessing GPU instances via the cloud.
- A comparison of leading cloud GPU providers for AI projects.
- Factors in selecting the right GPU options, including examples of the best GPUs.
- Major AI applications where GPU acceleration provides significant benefits.
- Important considerations around environment setup, data security, and cost management when using cloud GPUs.
CPU and GPU Role in AI
While Central Processing Units (CPUs) have traditionally been the primary workhorse in the data center, their architecture introduces some limitations when working with AI. The power of the CPU is still important, but the GPU has emerged as the king for processing AI tasks. This gap has widened further in 2026 as AI models grow in size and complexity.
- Sequential Tasks: CPUs are designed with fewer, but very powerful cores optimized for handling tasks one after another.
- Parallelism: Many AI and ML tasks, especially model training and deep learning, involve performing the same calculation across vast amounts of data simultaneously (like large-scale matrix operations).
- CPUs Struggle with Parallel AI Tasks: Their sequential design makes them inherently less suited for the massive parallelism required, leading to longer processing times.
In contrast, GPUs offer a different approach:
- GPU Parallel Architecture: GPUs contain thousands of smaller, specialized cores (like CUDA cores and Tensor Cores).
- Simultaneous Calculation: GPU architecture enables parallel processing at scale, executing thousands of calculations per second.
- Faster for AI: GPU acceleration makes them significantly faster than CPUs for the intense parallel tasks associated with AI and ML.
While CPUs remain important for general system operations, specialized GPU instances deliver the specific compute power needed for demanding AI workloads, drastically reducing calculation times.
Understanding Cloud GPU Hosting
Cloud GPU hosting is a service where cloud providers offer remote access to high-powered GPU resources in a secure data center. This lets organizations bypass the substantial investment and overhead of managing on-premise GPU servers by allowing them to rent cutting-edge hardware on demand via the cloud.
This model is now widely used by startups and enterprises alike as AI workloads move into production environments.
GPU Hosting introduces several advantages:
- Increased Scalability: Organizations can dynamically adjust GPU resources based on project demand, paying only for the compute capacity used.
- Forget About Hardware Management: Cloud hosting removes the complexities of purchasing, housing, cooling, powering, and maintaining physical GPU hardware. You can sit back and relax, leaving the complexities to the experts.
- GPU Choice and On-Demand Support: Cloud environments offer various GPU options, with hardware based on the latest technologies. Typically cloud GPU hosting offers efficient and highly optimized software stacks and a comprehensive level of technical support, helping you improve performance and simplifying deployment.
In 2026, many providers also include pre-configured AI environments to reduce setup time.
Choosing Your Cloud GPU Provider
Now let’s take a look at what the biggest GPU Hosting providers have to offer.
Selecting the right cloud provider is an important decision for optimizing both performance and cost for your AI projects. While many providers offer GPU instances, their specific hardware offerings, pricing structures, geographical reach, management tools, and focus areas can vary significantly. In 2026, this decision increasingly depends on inference pricing, GPU availability, and deployment speed.
Here’s a comparative look at some big players in the AI GPU hosting market:
#1: Atlantic.Net:
![]()
Atlantic.Net offers high-performance computing with dedicated and cloud servers powered by the latest and greatest of NVIDIA accelerated GPUs. Its GPU portfolio continues to align with current AI workloads such as LLM inference and fine-tuning in 2026. With a focus on providing great power and personalized support, this provider truly shines with a no-nonsense approach to high-end computing. The GPU hosts all had the industry-leading NVIDIA H100 NVL or L40S GPU inside, making them extremely well-suited for demanding generative AI workloads, large language model (LLM) training and inference, natural language processing (NLP), high-performance computing (HPC), and advanced graphics rendering. If there is one thing that complements powerful hardware better, it’s expert support and impressive uptime SLA. Such Service Level Agreements ensure an ideal, robust environment for mission-critical projects. Atlantic.Net somehow combines affordability with impeccable, expert-driven service.
Below is Atlantic.Net’s cloud control panel interface used to deploy and manage dedicated and GPU servers.
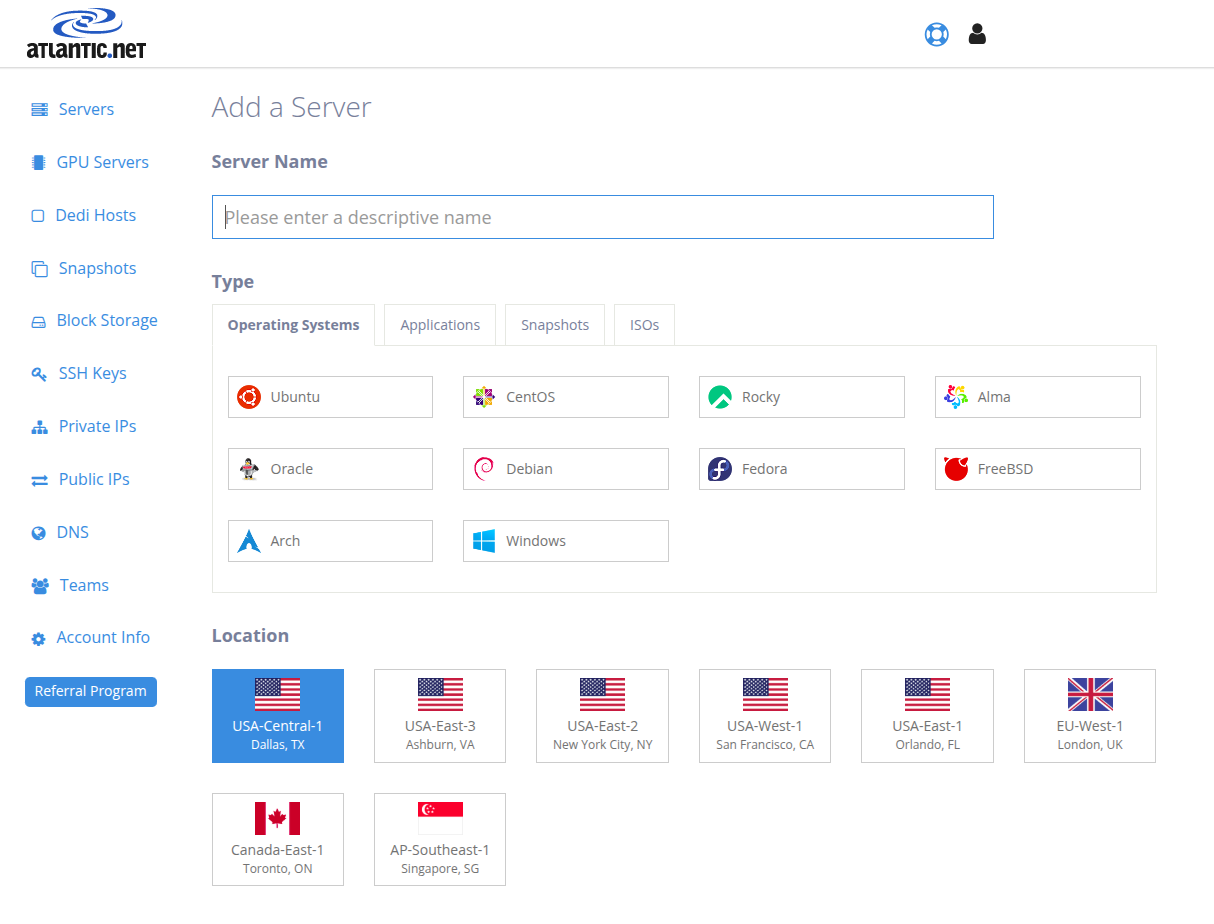
Image Source: Atlantic.Net
Advantages:
- Leading Hardware: Offers direct access to some of the most powerful and sought-after NVIDIA GPUs, such as the H100 NVL, right from the marketplace for top-tier performance on demanding AI training and inference tasks.
- Expert, Personalized Support: Offers a high-touch support model, giving access to skilled engineers directly, which is priceless for teams needing guidance on complex deployments, performance optimization, and troubleshooting.
- Transparent and Competitive Pricing: Clearly projects transparent, straightforward pricing, often considerably more economical than larger hyperscale providers, whereby high-performance computing is made accessible without complex billing.
Suitable For:
- AI Startups and Research Teams: These are organizations that badly need elite-level GPU power for their research and development but will prefer a provider which has easy pricing with dedicated technical support to speed up their projects.
- High-availability businesses that offer highly demanding requirements requiring powerful hardware with a strong uptime guarantee to ensure good uptime and performance consistently for mission-critical AI applications.
- Large Language Model and Generative AI Development Teams: Teams working on developing and fine-tuning large language models or other generative AI systems to take advantage of the full capabilities provided by the H100 and L40S GPUs’ high levels of VRAM and Tensor Core count.
#2: Amazon Web Services (AWS):

As the long-standing market leader, AWS provides an extensive choice of cloud services. EC2 offers various GPU instance families, such as the P4 series (NVIDIA A100), P5 series (NVIDIA H100), and G5 series (NVIDIA A10G), catering to diverse AI/ML training, inference, and graphics workloads, but its pricing models (On-Demand, Reserved Instances, Savings Plans, Spot Instances) can be complex to navigate and very expensive. In 2026, AWS continues expanding its AI infrastructure with newer GPU instance types and optimized AI services.
Here is the AWS EC2 dashboard, where you can control instances, monitor status, and configure settings.
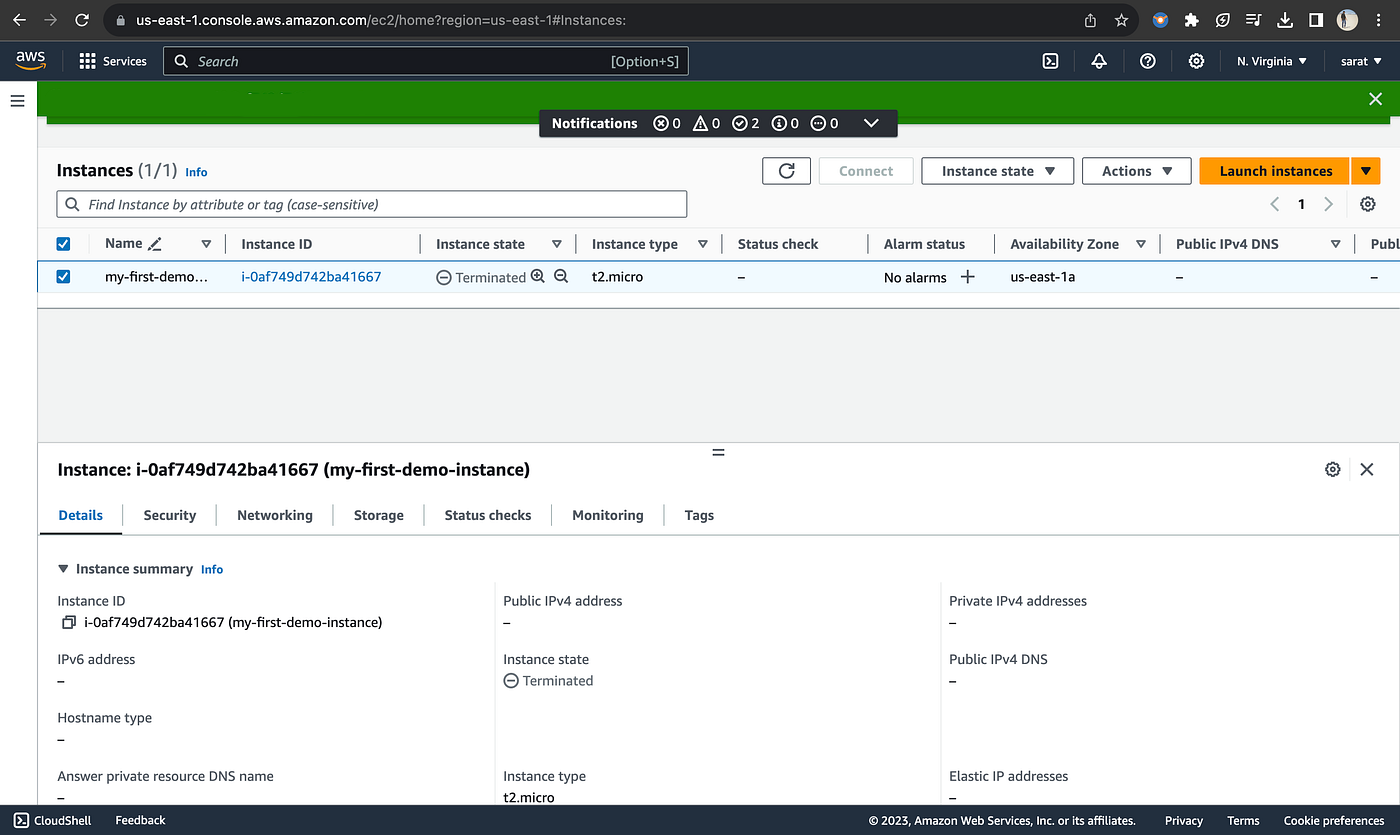
Image Source: AWS
Advantages
- Huge Service Platform: With this, it provides frictionless integration with the industry’s largest portfolio of cloud services: S3 for storage, SageMaker for ML pipelines, and Redshift for data warehousing, among others, to develop an integrated end-to-end platform.
- Global Reach and Scalability: Offers the ability to deploy GPU instances in several geographic regions, delivering low latency to global users and essentially limitless scalability for large AI training clusters.
- Variety of Instance Types: Delivers very fine granularity in choosing between GPU instances to allow teams to perfectly match their hardware-from older, cheaper GPUs all the way to the most recent H100s-to the exact performance and cost requirements of a given workload.
Ideal for:
- Large Enterprises: These have a considerable investment in the AWS ecosystem, who can deploy and manage AI workloads at scale by effectively leveraging their existing infrastructure, billing arrangements, and internal expertise.
- Complex, integrated workflows are projects requiring more than pure computing power to be harnessed into a wide array of other managed services for data processing, application hosting, and automation of DevOps.
- Diverse Teams: Those who use a wide range of AI applications, from very low-cost inference endpoints to massive, multi-node training jobs, and can benefit from having all the options from the one provider.
#3: Microsoft Azure:

Azure is another major cloud platform with deep integration within the Microsoft products. Azure offers N-series virtual machines equipped with a range of NVIDIA GPUs (e.g., T4, V100, A100, H100). It’s a great choice for businesses already embedded in Microsoft platforms, and the Reserved GPU pricing is competitive. However, limited open source support is available and typically costs more than their competitors. Azure’s AI ecosystem continues to grow in 2026 with tighter integration across enterprise tools and AI services.
Explore the Azure dashboard to organize resource groups, track usage, and manage cloud services from a centralized platform.
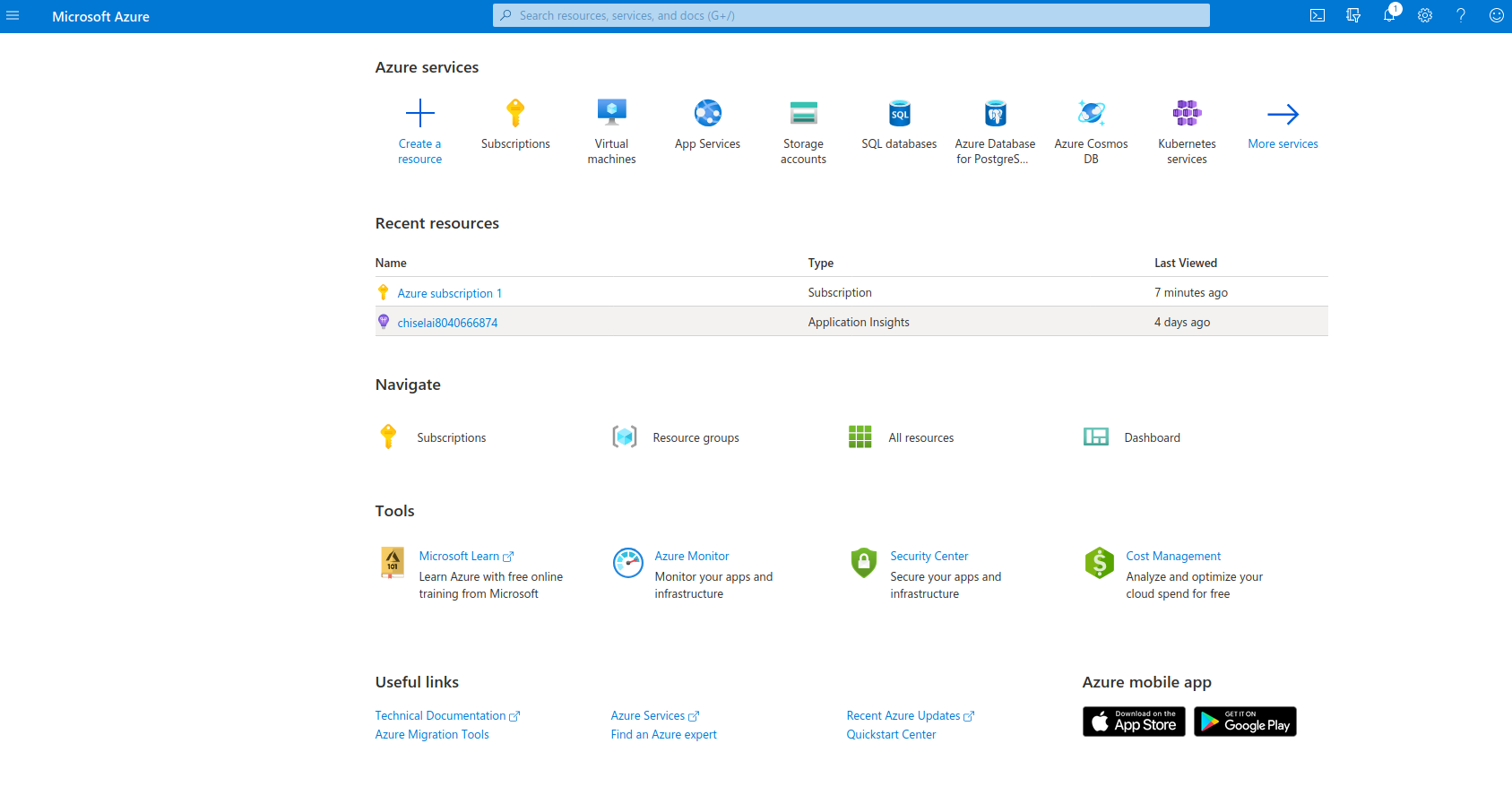
Image Source: Azure
Advantages:
- Deep Integration with Microsoft Products: Provides unparalleled native integration with essential enterprise tools like Azure Active Directory, Office 365, and Microsoft’s suite of data platforms for frictionless security, identity management, and data workflows.
- Strong Enterprise and Hybrid Cloud Focus: It provides robust solutions for hybrid cloud deployments, hence, the provision of Azure Arc, which enables each business to manage on-premise and cloud GPU resources through one control plane.
- All-in-One AI Platform: Hosts the Azure Machine Learning platform for end-to-end model creation, publishing, and management; it will certainly fit into large enterprise desires seeking a totally managed AI lifecycle.
Ideal for:
- For enterprises with deep commitment to the Microsoft stack, including Windows Server and SQL Server: They can quickly drive their AI initiatives by leveraging existing licenses and expertise on a platform they know.
- Hybrid Cloud Environments: For organizations that require keeping a mix of on-premise infrastructure with cloud resources due to regulatory, performance, or data sovereignty reasons and at the same time unify their manageability.
#4: Google Cloud Platform (GCP):

GCP is great at data analytics, AI/ML tooling (e.g., Vertex AI platform), and high-performance networking. Their Compute Engine instances are available with NVIDIA GPUs (A100, T4, L4, H100) and also offer their proprietary Tensor Processing Units (TPUs) optimized for specific ML frameworks like TensorFlow. GCP features a strong global network and good availability, however, like all of the major cloud providers, they are expensive. In 2026, TPUs remain a strong alternative for specific ML workloads, particularly within Google’s ecosystem.
Manage cloud services with the Google Cloud dashboard, where you can create virtual machines, deploy applications, and analyze data using built-in tools.
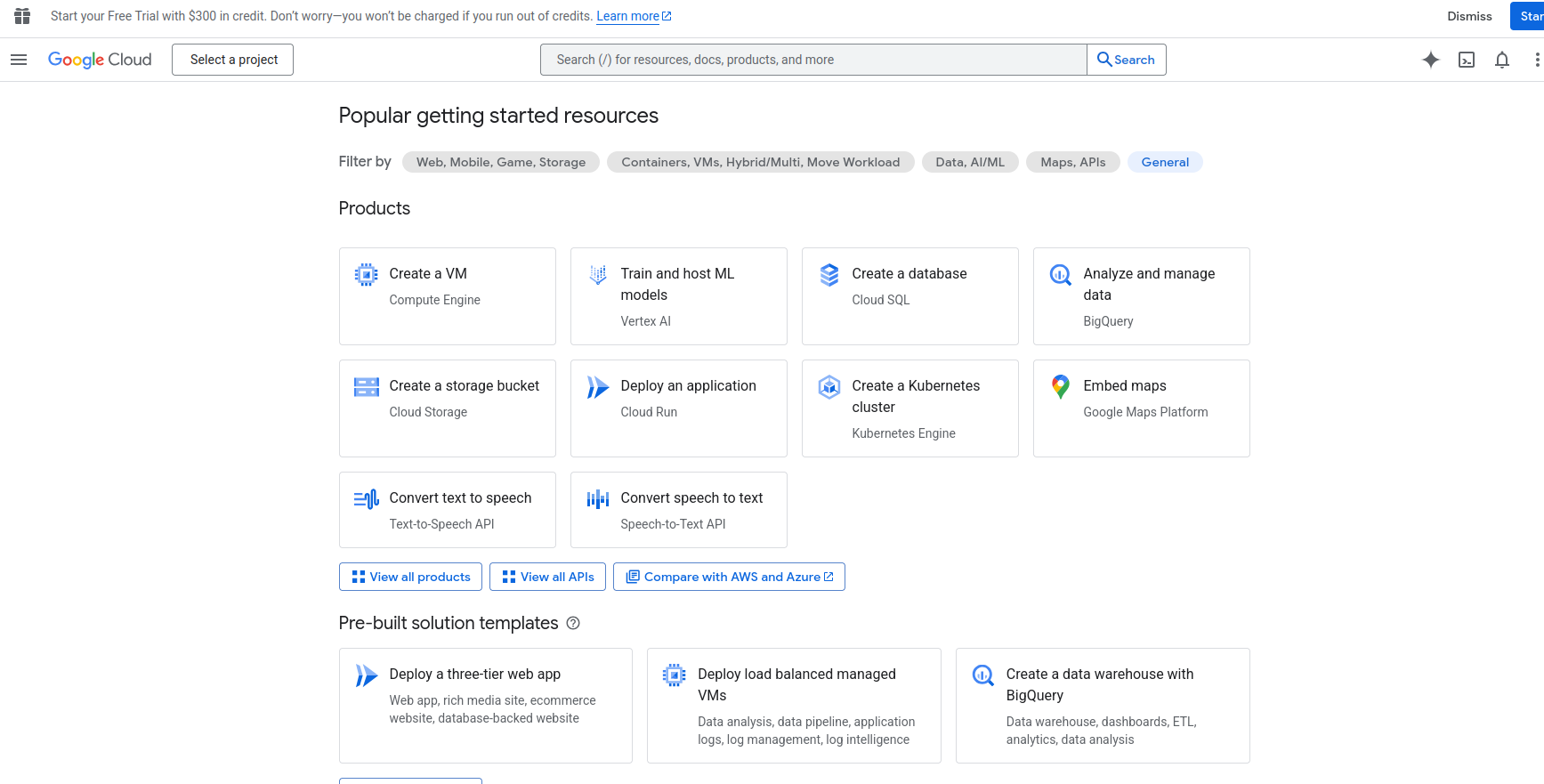
Image Source: Google Cloud
Advantages:
- AI and Data Tooling: Provides the Vertex AI platform, a unified and powerful managed environment for the entire ML lifecycle, along with data analytics services like BigQuery
- Access to Custom-Built TPUs: Offers Tensor Processing Units (TPUs) as an alternative to GPUs, which can deliver good performance-per-dollar for training large models built with frameworks like TensorFlow and JAX.
- High-Performance Networking: Boasts a global fiber optic network that provides low latency and high throughput, which is an advantage for distributed training jobs that span multiple GPU or TPU nodes.
Ideal For:
- Data-Centric Organizations: Companies whose AI strategies are deeply intertwined with large-scale data processing and analytics, allowing them integration between BigQuery and Vertex AI.
- TensorFlow and JAX Developers: Research and development teams that build their models using Google’s native frameworks and can take full advantage of the performance benefits offered by TPUs.
- Large-Scale Distributed Training: Projects that require training massive models across hundreds or thousands of nodes, where GCP’s high-performance networking and infrastructure can significantly reduce training times.
#5: Vultr:

A provider known for its developer-friendly approach and good pricing across a wide global network of data centers. Vultr has significantly expanded its NVIDIA GPU service (including A16, A40, A100, L40S, H100, GH200) and AMD Instinct accelerators (MI300X, MI325X). They offer both virtual machines and bare metal options, appealing to users seeking cost-effectiveness. One downside is that there is often limited capacity in specific regions, so double-check that your chosen region is available. Vultr continues expanding its GPU catalog into 2026, including newer NVIDIA and AMD accelerators.
Here is the Vultr cloud hosting interface. Where you can deploy new instances, manage Kubernetes clusters, and control storage and networking services.
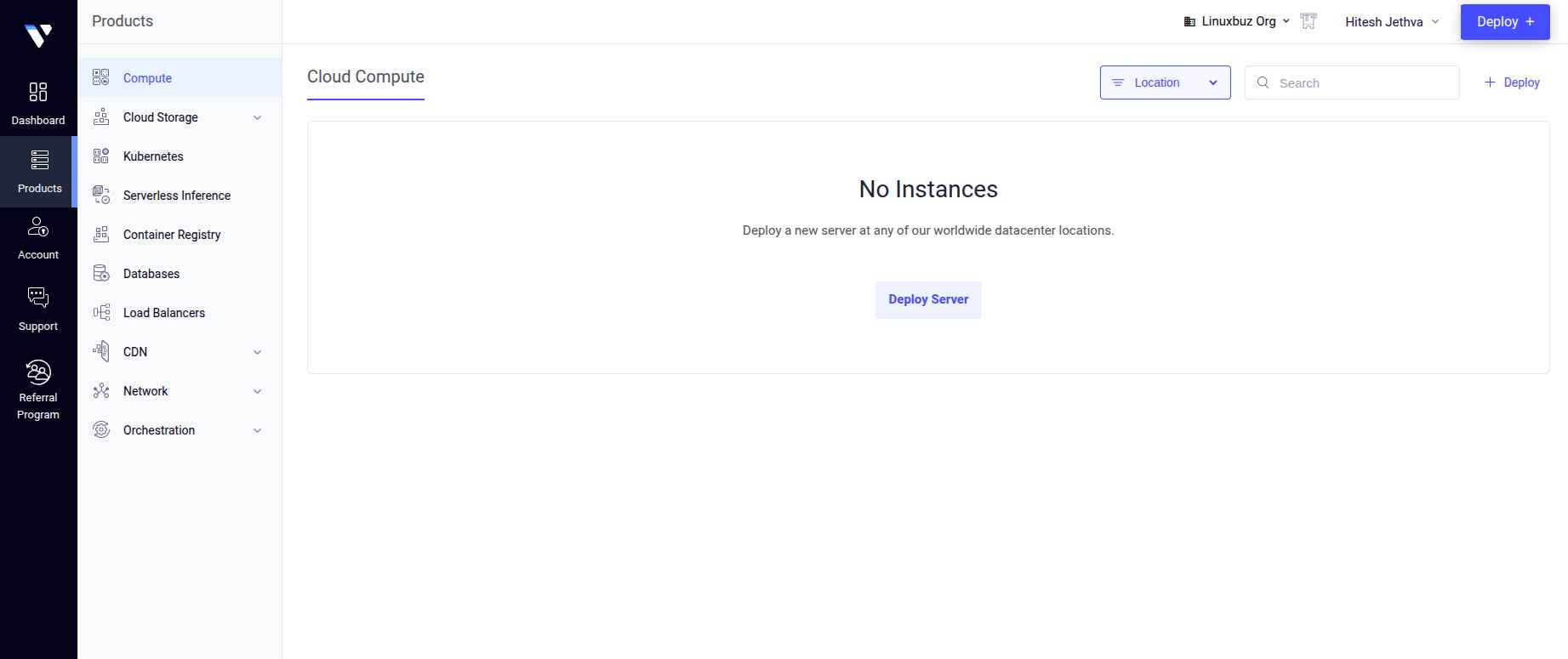
Image Source: Vultr
Advantages:
- Transparent Pricing: Known for its clear, predictable billing model makes an attractive option for developers and startups who are highly sensitive to cost.
- Broad GPU Selection (NVIDIA & AMD): A diverse hardware selections, including the latest GPUs from both NVIDIA and AMD, providing users with more options to find the perfect price-to-performance ratio for their needs.
- Bare Metal Options: Provides dedicated bare metal servers, giving users direct, un-virtualized access to the underlying hardware for maximum performance and control over the software stack, which is ideal for specialized or performance-critical workloads.
Ideal For:
- Developers and Startups: Individuals and small teams looking for an easy-to-use platform with affordable, on-demand GPU resources without the complexity and overhead of the larger cloud providers.
- Cost-Conscious AI Inference: Applications that need to run inference at scale and can benefit from the cost savings offered by Vultr’s fractional GPU instances or lower-cost hardware options.
- Users Needing Hardware Flexibility: Teams that want to experiment with different GPU architectures, including AMD’s Instinct accelerators, or require the raw performance and customization only available with bare metal servers.
#6: Lambda Labs:

A specialized cloud provider explicitly focused on serving AI and ML developers and researchers. Lambda offers on-demand and reserved access primarily to high-end NVIDIA GPUs (including H100, A100, GH200, and newer models like H200, B200). They are known for their pre-configured environments (Lambda Stack with popular ML frameworks), ease of setting up multi-GPU clusters with high-speed interconnects (InfiniBand), and transparent hourly pricing, making them a popular choice for demanding training tasks. Lambda remains popular in 2026 for its simplified setup and early access to new GPU hardware.
Let’s see the Lambda interface for analyzing resource usage, managing filesystems, and monitoring spending across projects.
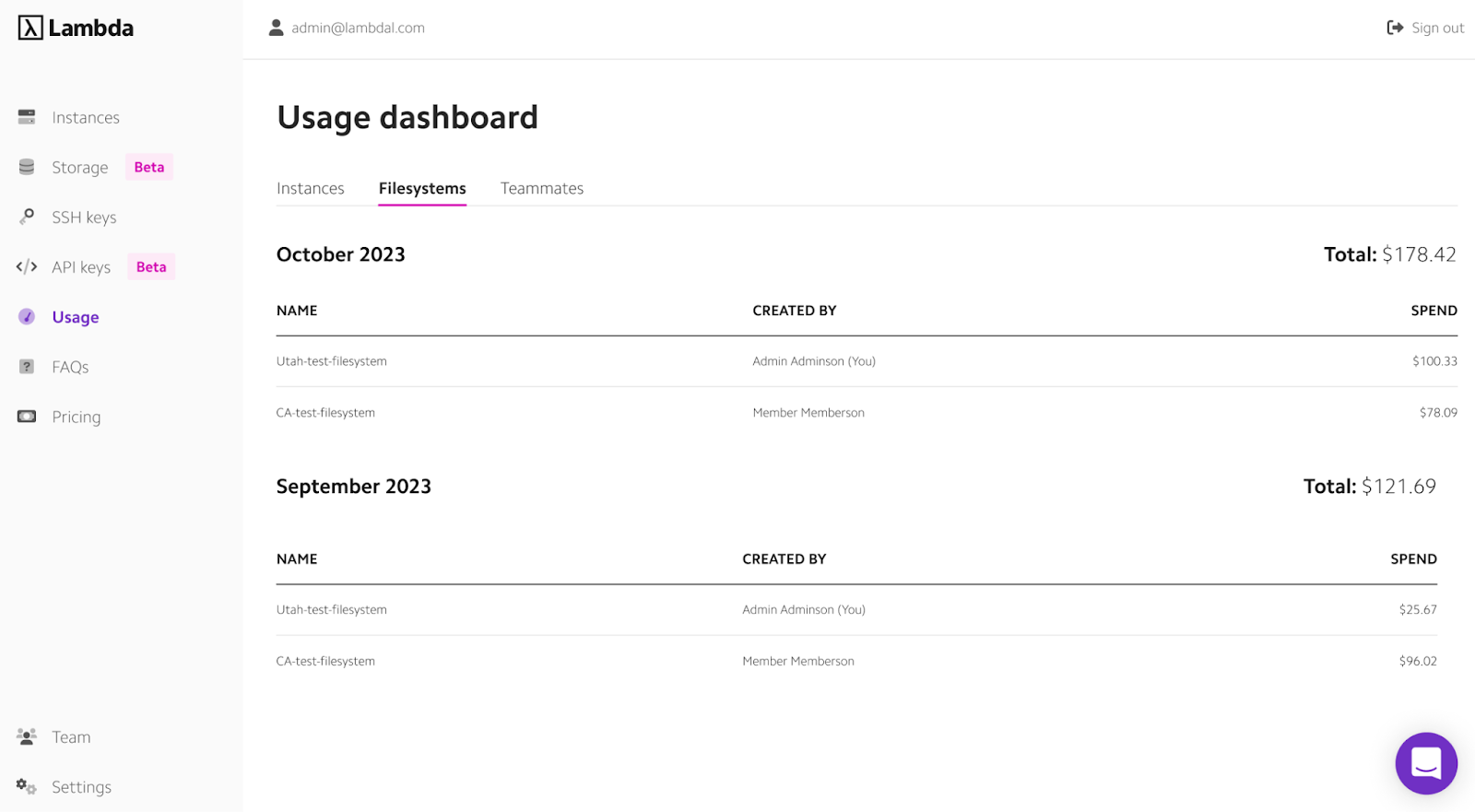
Image Source: Lambda
Advantages:
- Purpose-Built for AI/ML: The entire platform, from hardware selection to the software stack, is designed specifically for AI researchers and developers, eliminating the unnecessary complexity found in general-purpose clouds.
- Pre-configured Environments: The Lambda Stack comes pre-installed with drivers, CUDA, and major ML frameworks like PyTorch and TensorFlow, saving developers hours or even days of setup time and allowing them to start training immediately.
- Access to new GPUs: Often among the first providers to offer access to the very latest and most powerful NVIDIA GPUs, making it a top choice for researchers who need state-of-the-art hardware for their experiments.
Ideal For:
- AI Researchers and Practitioners: Individuals and teams whose primary focus is building and training deep learning models and who value a streamlined, hassle-free environment that lets them focus on their work, not on infrastructure management.
- Demanding Multi-GPU Training: Projects that require training large models across multiple GPUs, as Lambda makes it simple to provision multi-node clusters with the high-speed interconnects necessary for efficient distributed training.
- Users Who Prioritize Simplicity and Speed: Developers who want to avoid the steep learning curve and operational overhead of AWS, Azure, or GCP and prefer a straightforward, “it just works” solution for high-performance GPU computing.
Key Advantages of Using GPU Instances for AI/ML
Although deploying GPU instances in the cloud involves costs, this expense is often much lower than anticipated and is accompanied by significant benefits:
- Speed and Performance:
Powerful GPUs dramatically improve the processing speed for AI workloads. Don’t just take our word for it; check out our AI Procedures to experience the performance improvements today.
- Scalability:
AI projects have fluctuating needs. Cloud GPU hosting offers great scalability, allowing users to easily scale compute capacity on demand. Teams can start small and expand to multiple GPUs as models grow in complexity or datasets increase in scale.
- Cost-Effectiveness:
On-premise GPU clusters require significant upfront capital and ongoing costs. For example, an NVIDIA H100 GPU costs upwards of $25,000 at retail, and the NVIDIA L40S GPU costs about $10,000. Cloud GPU services use a pay-as-you-go model, making high-performance computing accessible and cost-effective without massive capital expenditure.
The Best GPUs for Your AI Applications
There are plenty of choices when it comes to selecting optimal GPU instances. In 2026, selection decisions are increasingly based on workload type, especially training vs inference. You need to consider the best for both performance and cost-efficiency. The ideal choice depends on specific tasks: the type of AI workload (e.g., training and inference, computer vision, natural language processing), model complexity, and data volume.
Cloud providers present various GPU options, with NVIDIA GPU technology prevalent. Understanding different tiers is necessary. Top-tier performance might be needed for training deep learning models on large datasets, while AI inference might suit more balanced or cost-effective GPUs.
Let’s take a further look at the options available.
Spotlight on NVIDIA GPUs: The Industry Standard
NVIDIA significantly leads the AI and high-performance computing (HPC) GPU market, built on powerful hardware and a reliable CUDA software ecosystem. CUDA enables developers to unlock the parallel processing capabilities of NVIDIA GPUs. Its dominance continues in 2026 due to both hardware performance and its CUDA ecosystem.
What to look for:
- CUDA Cores: Fundamental units for parallel execution; more cores generally mean higher computing power.
- Tensor Cores: Specialized cores accelerating the matrix operations foundational to deep learning, boosting deep learning performance.
- High Memory Bandwidth: Needed for rapid data transfer to keep cores fed, especially with large datasets.
High-end NVIDIA GPU models like the NVIDIA H100 NVL GPU represent the cutting edge for demanding AI workloads, including large language models (LLMs). Newer GPU generations are also emerging to address growing demand for AI compute.
Other models, like the NVIDIA L40S GPU, cater to graphics rendering and simulation, alongside AI development.
Understanding GPU Specifications
When evaluating GPU options, several technical specifications are important:
- VRAM (Video RAM): Dedicated GPU memory. Training large deep learning models or processing high-resolution data demands substantial VRAM.
- Memory Bandwidth: The speed of data transfer between VRAM and cores. High memory bandwidth is necessary for preventing bottlenecks with large datasets.
- FLOPS (Floating-Point Operations Per Second): Quantifies raw computational throughput.
Take time to analyze these specs when selecting your next GPU instance.
Core Applications Accelerated by GPU Hosting
Cloud GPUs provide the necessary power for a wide range of computationally intensive tasks.
Here are some key areas where GPU acceleration makes a significant difference:
- Deep Learning Model Training: This is often the most demanding AI workload. Training deep learning models, especially large language models (LLMs), requires immense computing power (CUDA Cores, Tensor Cores), substantial VRAM to hold models and large datasets, and high memory bandwidth. High-performance GPUs, such as the NVIDIA H100 NVL GPU, are favored, and using multiple GPUs is common to reduce training time.
- AI Inference: Once a model is trained, AI inference involves using it to make predictions on new data. While still requiring significant compute for complex models or real-time processing, the priorities often shift to low latency (fast responses) and high throughput (predictions per second), potentially using different classes of GPU instances optimized for efficiency.
- Machine Learning: Beyond deep learning, many advanced machine learning models operating on large datasets benefit from GPU acceleration, speeding up model training and analysis compared to CPU-only approaches.
- Computer Vision: Analyzing images and video requires processing large amounts of data. GPUs excel here due to their parallel processing capabilities and high memory bandwidth, enabling tasks like object detection and real-time processing of visual streams. Ample VRAM is also often necessary.
- Natural Language Processing (NLP): Similar to general deep learning, training large NLP models demands lots of GPU resources. Inference for applications like translation or chatbots benefits from GPU speeds, often focusing on responsiveness.
- Scientific Simulations & High-Performance Computing (HPC): GPUs are essential tools in high-performance computing tasks, driving complex scientific simulations in physics, chemistry, climate modeling, and more. These applications often need the maximum available computing power and benefit from the GPU’s ability to handle large-scale parallel processing.
- Graphics Rendering & Simulation: For tasks like high-fidelity 3D rendering, animation, or complex engineering simulations, GPUs designed with strong graphics capabilities, like the NVIDIA L40S GPU, provide the necessary performance.
Setting Up and Securing Your Cloud GPU Environment
Transitioning to cloud GPU hosting involves careful planning for both setup and ongoing security.
Environment Setup:
Select a cloud provider based on GPU instance availability, pricing, location, reliability, and support. Then, configure your GPU instance by choosing an OS, installing drivers (NVIDIA drivers, CUDA toolkit), and setting up AI ML libraries/ML frameworks (TensorFlow, PyTorch).
Many providers offer pre-built images or templates with the required software stack to accelerate deployment and provide faster deployment times.
Ensuring Data Security in AI Models:
It’s critical to secure your configured environment, especially when handling sensitive data or when adhering to regulations (GDPR, HIPAA, CCPA) or meeting compliance requirements.
Implement these key data security best practices for added protection:
- Encryption: Use strong encryption for data at rest and in transit.
- Identity and Access Management (IAM): Apply least privilege principles with strong authentication and role-based access controls for GPU instances, storage, and data.
- Network Security: Use VPCs, strict firewall rules, and private endpoints to isolate GPU resources.
- Monitoring, Logging, and Auditing: Log activities, monitor for anomalies, and conduct regular audits to meet compliance requirements.
- Secure Artifact Management: Store trained AI models and scripts in secure repositories.
In 2026, AI governance and model monitoring are becoming standard security practices.
Conclusion
GPU hosting is foundational for advancing artificial intelligence. Accessing vast parallel processing power and specialized compute via the cloud allows organizations to tackle complex problems faster.
Cloud GPUs provide the necessary infrastructure, scalability, speed, and performance for everything from deep learning research to real-time processing in AI applications. As AI systems move from experimentation to production in 2026, reliable GPU infrastructure is a core requirement for success.
As AI and GPU capabilities co-evolve, their interdependence deepens, unlocking new possibilities.
Want to learn more about Atlantic.Net GPU Hosting? Contact our team today to unlock our newest service.
* This post is for informational purposes only and does not constitute professional, legal, financial, or technical advice. Each situation is unique and may require guidance from a qualified professional.
Readers should conduct their own due diligence before making any decisions.